
Artificial Intelligence systems face a fundamental problem. They learn well when trained once on a fixed dataset. But in the practical world things are quite different. Data changes, new tasks are introduced, and users evolve constantly. Continual learning is the field of AI that directly handles this problem.
What is Continual Learning?
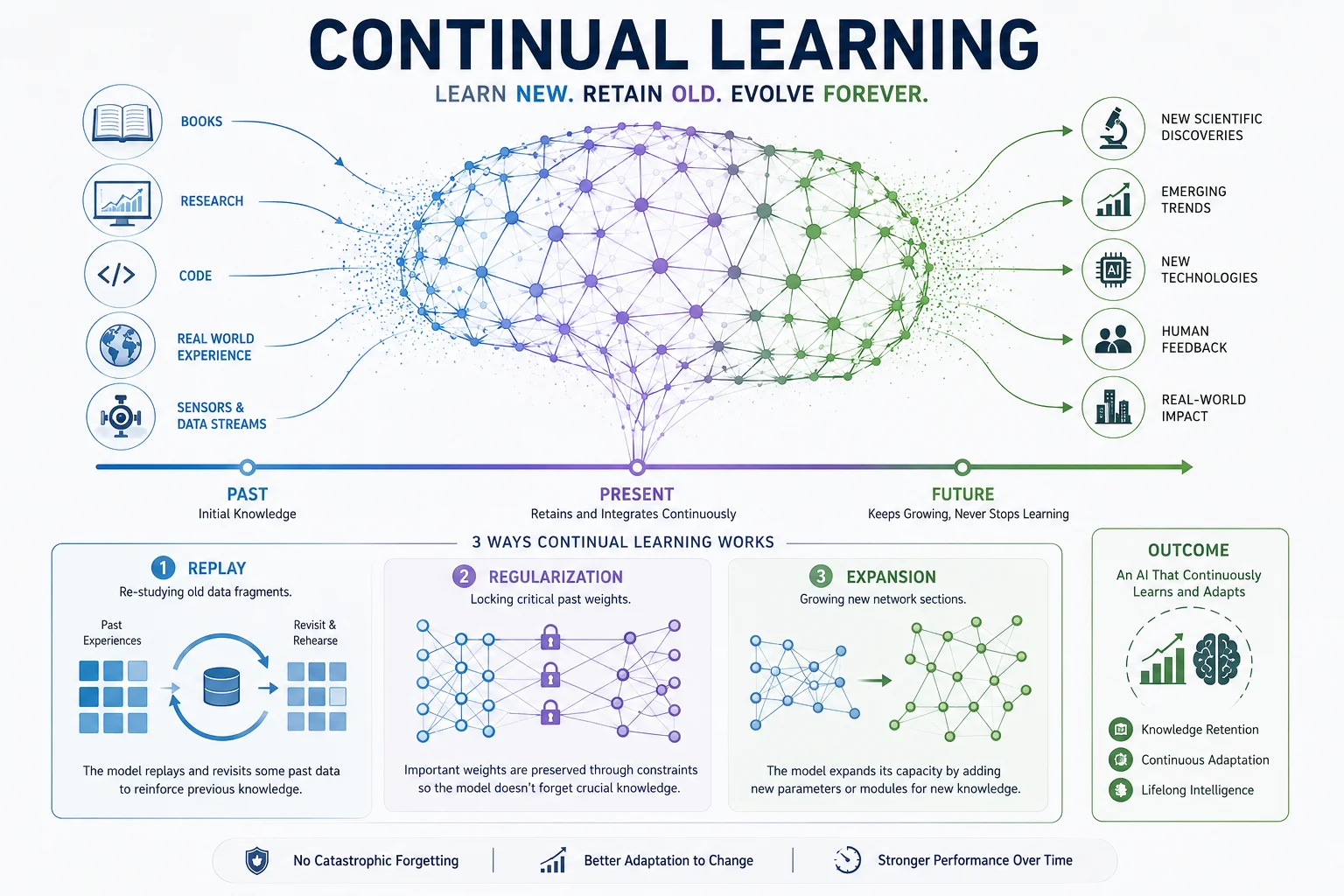
Continual learning is an Artificial Intelligence training method where a model constantly learns new abilities or data over time without forgetting past knowledge. In contrast to the static nature of traditional AI, continual learning mimics human learning by adapting to a changing world while retaining its original capabilities.
3 Ways It Works:
Replay: Re-studying old data fragments.
Regularization: Locking critical past weights.
Expansion: Growing new network sections.
Continual learning gives AI systems the ability to develop themselves adaptively. It provides a foundation for models to keep learning over time, acquiring new knowledge while retaining the information that they already know. It is also commonly known as lifelong learning or incremental learning. All three terms describe the same fundamental goal: sequential knowledge acquisition without forgetting.
Why do Neural Networks Forget What They Already Learned?
This is the central problem in the field. It is called catastrophic forgetting.
1. Overwriting Problem (Catastrophic Forgetting)
A neural network stores knowledge within a massive, interconnected web of adjustable mathematical values called weights. When you teach a network a new task, it must change and recalculate these exact numbers to optimize its performance for the new objective. Because it uses the same shared numbers for everything, updating them for a new task accidentally overwrites the precise configuration used for previous tasks. This internal memory wipe causes an instant, drastic drop in past performance, known as catastrophic forgetting.
2. "Fresh Start" Flaw
This forgetting happens because standard AI models treat every new training session like a brand-new, isolated problem. The system focuses 100% on mastering the new data in front of it to succeed right away. Because it operates with no memory of its past training, it has no built-in rules or safety mechanisms to protect, shield, or lock the old numerical settings it used before.
3. Generative AI Bottleneck
This lack of an internal safety lock creates a major roadblock for modern Generative AI, like Large Language Models (LLMs). When engineers try to fine-tune a chatbot with new skills or facts, a damaging trade-off happens. As the model changes its settings to learn the new data, it frequently breaks or completely loses its grasp on its previously learned general knowledge, logic, and natural communication skills.
4. Biological Advantage (How Humans Differ)
Humans naturally solve this issue. A person does not suddenly forget how to ride a bicycle just because they learned how to drive a car. The human brain protects past knowledge through a biological process called synaptic consolidation. Once you master a skill, your brain chemically cements and shields the vital neural connections responsible for it, thus preventing new experiences from overwriting them. Continual learning research uses this biological insight to design AI software algorithms with similar protective locks.
How Does Continual Learning Differ from Traditional Machine Learning?
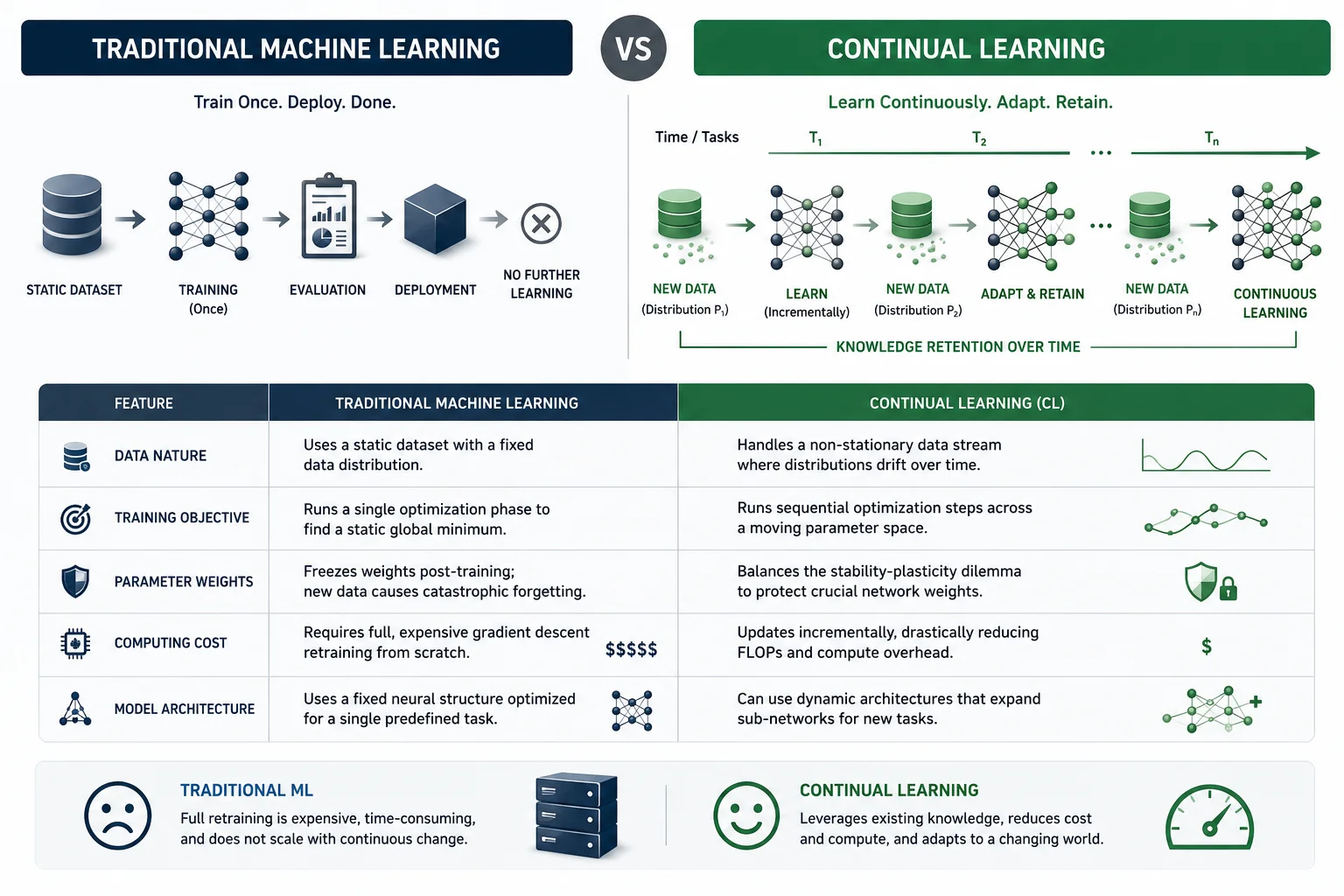
Traditional Machine Learning assumes a static dataset. The model trains once on the data, gets evaluated, and gets deployed. That is the end of the learning process. Continual learning rejects that assumption entirely.
The aim of continual learning is to incrementally incorporate new knowledge, adapt to diverse tasks across evolving domains, and retain previously acquired capabilities throughout the learning process.
Feature | Traditional Machine Learning | Continual Learning (CL) |
Data Nature | Uses a static dataset with a fixed data distribution (P(X,Y)). | Handles a non-stationary data stream where distributions drift over time. |
Training Objective | Runs a single optimization phase to find a static global minimum. | Runs sequential optimization steps across a moving parameter space. |
Parameter Weights | Freezes weights post-training; new data causes catastrophic forgetting. | Balances the stability-plasticity dilemma to protect crucial network weights. |
Computing Cost | Requires full, expensive gradient descent retraining from scratch. | Updates incrementally, drastically reducing FLOPs and compute overhead. |
Model Architecture | Uses a fixed neural structure optimized for a single predefined task. | Can use dynamic architectures that expand sub-networks for new tasks. |
There is also a practical cost dimension attached with traditional machine learning. Compared to training from scratch, continual learning makes use of pre-acquired knowledge to drastically reduce computational overhead and improve training efficiency, while sustaining state-of-the-art performance. For LLMs like GPT-3 class models, full retraining is financially and computationally prohibitive. Continual learning is therefore not just an academic exercise but an operational necessity.
What are the Three Core Strategies for Continual Learning?
Researchers usually use three main strategies for Continual Learning:
Regularization-based approaches that constrain weight updates to preserve important parameters,
Replay-based methods that retain and revisit previous experiences, and
Architectural strategies that allocate dedicated network capacity for different tasks.
How Does Regularization Prevent Forgetting?
Regularization-based methods add a penalty term to the loss function during new task training. This penalty discourages the model from changing weights that were critical for previous tasks. The idea is to make the optimization landscape aware of past knowledge, not just current task performance.
Elastic Weight Consolidation (EWC) and Synaptic Intelligence estimate parameter importance and maintain model stability by penalizing large changes in important parameters. Both methods calculate a per-weight importance score. Weights that were more influential for old tasks receive stronger protection.
More specifically, EWC works by selectively slowing down learning on certain weights based on how important they are to previously seen tasks. It constrains important parameters to stay close to their old values. The importance of each parameter is estimated using the Fisher information matrix, which measures how sensitive the model's output is to changes in that parameter.
Synaptic Intelligence measures the weights' importance through the help of synapses. It uses three-dimensional synaptic representations rather than one-dimensional weights. This allows it to preserve much more knowledge and prevent important synapses from changing.
Another regularization approach worth noting is Learning without Forgetting (LwF). LwF retains the knowledge of previous steps by using knowledge distillation to encourage the current model to behave similarly to the models trained on previous tasks. Rather than storing old data or estimating parameter importance, LwF replays the model's own past predictions as soft supervision signals.
How Does Replay Keep Old Memories Alive?
Researchers use replay-based methods to fix the problem of AI models often forgetting old skills when learning new ones. This is actually inspired by how the human brain saves memories.
Core Replay Strategies
Experience Replay: Stores a small sample of old data and mixes it with new data during training.
Gradient Episodic Memory (GEM): Uses past samples to ensure new updates do not harm old skills.
Generative Replay: Replaces stored data or memory buffer with a generative AI model that recreates fake, realistic past examples (pseudo data). This addresses the concerns that arise from storing raw data from past tasks. This means the model learns to synthesize its own memory rather than keeping a literal archive of old examples.
What Do Architectural Strategies Do Differently?
Unlike other methods, architectural strategies change the physical structure of the AI model instead of changing its data or training rules.
Core Architectural Strategies
Progressive Neural Networks: Retain previously trained models as knowledge and build new parts alongside them to link old and new knowledge.
Copy Weights with Re-initialization: Isolate and freeze specific internal parts of the model for each individual task.
Hybrid Methods: Combine structural changes with training rules to get the best of both worlds.
The tradeoff here is scale. Scalability remains an issue with architectural approaches because the network parameters grow as the number of tasks increases. This becomes a significant constraint in production deployments where dozens or hundreds of tasks may accumulate over time. Hybrid methods have shown more balanced results in recent benchmarks.
What Are the Three Learning Scenarios in Continual Learning?
Researchers also categorize continual learning by the type of task shift the model encounters. There are three standard scenarios.
In task-incremental learning, the model knows which task it is performing at test time. Task identity is available as context.
In domain-incremental learning, the task category remains the same but the input distribution shifts. For example, a sentiment classifier trained on product reviews that then encounters social media text faces a domain shift without a task shift.
In class-incremental learning, the model must classify an expanding set of classes with no task identity provided at inference time. Class-incremental learning is recognized as one of the most challenging scenarios in the field and has been the subject of dedicated survey work in the IEEE Transactions on Pattern Analysis and Machine Intelligence. This is the scenario closest to real-world deployment conditions.
How is Continual Learning Being Applied to Large Language Models (LLMs)?
Traditional AI models are trained once on a fixed dataset, which means their knowledge quickly becomes outdated. For modern LLMs to stay useful, they must constantly learn new information without forgetting the information that they already know.
Because LLMs are massive and generate text in a step-by-step manner, older AI learning methods do not work well. Instead, engineers apply continual learning across three distinct stages of an LLM's life cycle:
Continual Pre-training: This involves injecting fresh, real-world data and new domain knowledge into the base model.
Continual Fine-tuning: Here, the model is taught how to perform new specific tasks or follow new instructions.
Continual Alignment: This involves correcting the model's behavior to keep it safe, helpful, and accurate over time.
To update these massive models efficiently without breaking their existing knowledge, researchers depend on parameter-efficient tools like LoRA (Low-Rank Adaptation), specialized scaling laws, and Mixture-of-Experts systems.
Where is Continual Learning Being Used in the Real World?
Continual learning is actively used in real-world engineering and production systems. Tech companies, automotive manufacturers, and medical researchers have deployed specific frameworks to handle streaming data without deleting past knowledge.
Deployment examples of Continual Learning from real world implementations across multiple industries:
1. Large Language Models (LLMs) & Finance: BloombergGPT
Implementation: Financial firms cannot depend only on static LLMs because market terms, stock tickers, and economic contexts change daily. In developing BloombergGPT, researchers utilized Domain-Adaptive Continual Pre-training (DAPT).
How it works: Instead of retraining a massive model from scratch when new data arrives, they continually feed a streaming, unlabeled financial corpus into an existing general language model. This infuses new domain terminology into the model's parameters while maintaining its base reasoning capabilities.
2. Autonomous Driving: Tesla’s Occupancy Network
Implementation: In autonomous systems, a self-driving vehicle cannot completely reset its artificial intelligence every time it encounters a new city, unique weather, or rare construction zones.
How it works: Tesla transitioned its Full Self-Driving (FSD) stack toward an end-to-end world model network. The vision system processes vast streams of video data collected across millions of vehicles. It uses data-driven joint loss functions to compress new driving scenarios directly into the network parameters. This is done without erasing fundamental navigation rules like lane-keeping and braking.
3. Recommendation Systems: Pinterest (PinSage) & Alibaba (AliGraph)
Implementation: E-commerce and social media platforms experience massive "data drift" as user trends change hourly. Therefore, reconstructing a global recommendation matrix every day is computationally impossible.
How it works: According to production research compiled by Emerald Insight and the ACM Digital Library, systems like Pinterest's PinSage and Alibaba's AliGraph operate on massive graph structures containing billions of edges. They use streaming dataset distillation and incremental graph updates. When a user interacts with a new product, the system performs a localized gradient update to capture the immediate change in taste without forgetting the user's historical core preferences.
4. Healthcare AI: Multi-Hospital EHR & Imaging Deployments
The Implementation: If a diagnostic model trained at Hospital A is deployed at Hospital B, it faces new patient demographics and different imaging equipment. Simply fine-tuning the model on Hospital B's data causes "catastrophic forgetting.” This makes it less accurate when analyzing data from Hospital A.
How it works: Real-world clinical research documented in Nature and The Lancet Digital Health shows the use of experience replay-based clinical agents. As the AI adapts to new patient cohorts sequentially (Hospital A → Hospital B → Hospital C), it retains a tiny, securely anonymized memory buffer of historical patient cases. The model replays past data alongside new data to balance "rigidity" (saving old knowledge) and "plasticity" (learning new hospitals).
What are the Challenges of Continual Learning?
The field has made real progress. However, several hard problems persist.
First, there is no universal benchmark. Comparing different AI systems remains highly difficult because researchers use entirely different datasets, test orders, and scoring metrics to evaluate their models.
Second is strategy conflicts. Using a combination of three core strategy families (regularization, replay, and changing model architecture) into a single, cohesive system is incredibly complex; often, one method accidentally cancels out the benefits of another.
Third, fairness and bias amplification remain underexplored. As an AI continuously updates on streaming data from the real-world, it risks absorbing and compounding societal biases, stereotypes, or errors present in newer datasets over time.
Fourth is recency and task bias. Models naturally develop a heavy blind spot called recency bias. It causes them to over-favor newly introduced data profiles while discarding historical context
Open research directions include memory-efficient learning, adaptive self-supervised techniques, and fairness-aware continual learning, all of which are needed before continual learning systems can be deployed responsibly at scale.
What Does the Future of Continual Learning Look Like?
For continual learning, the trajectory is clear. As AI systems are expected to operate for years in our changing world, the ability to learn without forgetting has become non-negotiable.
One of the most urgent tasks in AI at present is to keep giant language models up to date with fresh facts and dynamic user preferences. In fact, a dedicated tutorial at the 2025 EMNLP conference highlighted the importance of this issue in modern AI engineering.
The next exciting frontiers include:
Brain-Inspired Memory: Developing AI systems that mimic the human brain by separating quick, everyday experiences (episodic memory) from long-term factual knowledge (semantic memory).
Multimodal Learning: Teaching AI to continuously learn from text, images, video, and audio all at the same time without breaking.
Expanding Across AI Types: Moving beyond text to apply continual learning to vision-language models, robotics, and image-generating diffusion models.
Continual learning is essentially trying to build a fundamental biological capability into software. The challenge is incredibly hard, the stakes are high, and the field is moving so fast that cutting-edge methods implemented today might be outdated by the time a company finishes deploying it.

Priyank Jha
Priyank is a Senior Content Developer and Strategist at SNVA Veranda. Earlier, he worked as a data scientist, where he gained extensive experience in developing data-driven solutions, advanced analytics, and strategic decision-making processes. His expertise includes data analysis, business intelligence, and implementing data-centric strategies that drive organizational growth and innovation. In addition to his data science experience, Priyank has over 10 years of experience in the banking and financial services sector. He has worked across various roles and operational levels, gaining in-depth knowledge of financial operations, customer service management, and business processes.
Learn how we research, review, and update our content. Editorial Standards & Review Process.

Latest Blogs
8 PhD in Business Careers: Academic and Industry Paths After Graduation (2026 Guide)
PhD in Business Careers: Academic and Industry Paths After Graduation (2026 Guide) Is an Online DBA Worth It? Salary, ROI, and Career Benefits (2026 Guide)
Is an Online DBA Worth It? Salary, ROI, and Career Benefits (2026 Guide) PhD vs DBA: Which Doctorate Is Right for You? (2026 Complete Guide)
PhD vs DBA: Which Doctorate Is Right for You? (2026 Complete Guide) How to Compare Online DBA Programs: A Step-by-Step Guide Before You Apply
How to Compare Online DBA Programs: A Step-by-Step Guide Before You Apply  Doctor of Business Administration Careers: Jobs, Salary & Growth in 2026
Doctor of Business Administration Careers: Jobs, Salary & Growth in 2026 Why Does a DBA Make More Sense Than a PhD?
Why Does a DBA Make More Sense Than a PhD? DBA vs PhD: Which Doctoral Degree Holds Higher Academic Value?
DBA vs PhD: Which Doctoral Degree Holds Higher Academic Value? Online DBA Degree Explained: Curriculum, Admission, and Career Opportunities (2026 Guide)
Online DBA Degree Explained: Curriculum, Admission, and Career Opportunities (2026 Guide)
Featured Courses




Artificial Intelligence systems face a fundamental problem. They learn well when trained once on a fixed dataset. But in the practical world things are quite different. Data changes, new tasks are introduced, and users evolve constantly. Continual learning is the field of AI that directly handles this problem.
What is Continual Learning?
Continual learning is an Artificial Intelligence training method where a model constantly learns new abilities or data over time without forgetting past knowledge. In contrast to the static nature of traditional AI, continual learning mimics human learning by adapting to a changing world while retaining its original capabilities.
3 Ways It Works:
Replay: Re-studying old data fragments.
Regularization: Locking critical past weights.
Expansion: Growing new network sections.
Continual learning gives AI systems the ability to develop themselves adaptively. It provides a foundation for models to keep learning over time, acquiring new knowledge while retaining the information that they already know. It is also commonly known as lifelong learning or incremental learning. All three terms describe the same fundamental goal: sequential knowledge acquisition without forgetting.
Why do Neural Networks Forget What They Already Learned?
This is the central problem in the field. It is called catastrophic forgetting.
1. Overwriting Problem (Catastrophic Forgetting)
A neural network stores knowledge within a massive, interconnected web of adjustable mathematical values called weights. When you teach a network a new task, it must change and recalculate these exact numbers to optimize its performance for the new objective. Because it uses the same shared numbers for everything, updating them for a new task accidentally overwrites the precise configuration used for previous tasks. This internal memory wipe causes an instant, drastic drop in past performance, known as catastrophic forgetting.
2. "Fresh Start" Flaw
This forgetting happens because standard AI models treat every new training session like a brand-new, isolated problem. The system focuses 100% on mastering the new data in front of it to succeed right away. Because it operates with no memory of its past training, it has no built-in rules or safety mechanisms to protect, shield, or lock the old numerical settings it used before.
3. Generative AI Bottleneck
This lack of an internal safety lock creates a major roadblock for modern Generative AI, like Large Language Models (LLMs). When engineers try to fine-tune a chatbot with new skills or facts, a damaging trade-off happens. As the model changes its settings to learn the new data, it frequently breaks or completely loses its grasp on its previously learned general knowledge, logic, and natural communication skills.
4. Biological Advantage (How Humans Differ)
Humans naturally solve this issue. A person does not suddenly forget how to ride a bicycle just because they learned how to drive a car. The human brain protects past knowledge through a biological process called synaptic consolidation. Once you master a skill, your brain chemically cements and shields the vital neural connections responsible for it, thus preventing new experiences from overwriting them. Continual learning research uses this biological insight to design AI software algorithms with similar protective locks.
How Does Continual Learning Differ from Traditional Machine Learning?
Traditional Machine Learning assumes a static dataset. The model trains once on the data, gets evaluated, and gets deployed. That is the end of the learning process. Continual learning rejects that assumption entirely.
The aim of continual learning is to incrementally incorporate new knowledge, adapt to diverse tasks across evolving domains, and retain previously acquired capabilities throughout the learning process.
Feature | Traditional Machine Learning | Continual Learning (CL) |
Data Nature | Uses a static dataset with a fixed data distribution (P(X,Y)). | Handles a non-stationary data stream where distributions drift over time. |
Training Objective | Runs a single optimization phase to find a static global minimum. | Runs sequential optimization steps across a moving parameter space. |
Parameter Weights | Freezes weights post-training; new data causes catastrophic forgetting. | Balances the stability-plasticity dilemma to protect crucial network weights. |
Computing Cost | Requires full, expensive gradient descent retraining from scratch. | Updates incrementally, drastically reducing FLOPs and compute overhead. |
Model Architecture | Uses a fixed neural structure optimized for a single predefined task. | Can use dynamic architectures that expand sub-networks for new tasks. |
There is also a practical cost dimension attached with traditional machine learning. Compared to training from scratch, continual learning makes use of pre-acquired knowledge to drastically reduce computational overhead and improve training efficiency, while sustaining state-of-the-art performance. For LLMs like GPT-3 class models, full retraining is financially and computationally prohibitive. Continual learning is therefore not just an academic exercise but an operational necessity.
What are the Three Core Strategies for Continual Learning?
Researchers usually use three main strategies for Continual Learning:
Regularization-based approaches that constrain weight updates to preserve important parameters,
Replay-based methods that retain and revisit previous experiences, and
Architectural strategies that allocate dedicated network capacity for different tasks.
How Does Regularization Prevent Forgetting?
Regularization-based methods add a penalty term to the loss function during new task training. This penalty discourages the model from changing weights that were critical for previous tasks. The idea is to make the optimization landscape aware of past knowledge, not just current task performance.
Elastic Weight Consolidation (EWC) and Synaptic Intelligence estimate parameter importance and maintain model stability by penalizing large changes in important parameters. Both methods calculate a per-weight importance score. Weights that were more influential for old tasks receive stronger protection.
More specifically, EWC works by selectively slowing down learning on certain weights based on how important they are to previously seen tasks. It constrains important parameters to stay close to their old values. The importance of each parameter is estimated using the Fisher information matrix, which measures how sensitive the model's output is to changes in that parameter.
Synaptic Intelligence measures the weights' importance through the help of synapses. It uses three-dimensional synaptic representations rather than one-dimensional weights. This allows it to preserve much more knowledge and prevent important synapses from changing.
Another regularization approach worth noting is Learning without Forgetting (LwF). LwF retains the knowledge of previous steps by using knowledge distillation to encourage the current model to behave similarly to the models trained on previous tasks. Rather than storing old data or estimating parameter importance, LwF replays the model's own past predictions as soft supervision signals.
How Does Replay Keep Old Memories Alive?
Researchers use replay-based methods to fix the problem of AI models often forgetting old skills when learning new ones. This is actually inspired by how the human brain saves memories.
Core Replay Strategies
Experience Replay: Stores a small sample of old data and mixes it with new data during training.
Gradient Episodic Memory (GEM): Uses past samples to ensure new updates do not harm old skills.
Generative Replay: Replaces stored data or memory buffer with a generative AI model that recreates fake, realistic past examples (pseudo data). This addresses the concerns that arise from storing raw data from past tasks. This means the model learns to synthesize its own memory rather than keeping a literal archive of old examples.
What Do Architectural Strategies Do Differently?
Unlike other methods, architectural strategies change the physical structure of the AI model instead of changing its data or training rules.
Core Architectural Strategies
Progressive Neural Networks: Retain previously trained models as knowledge and build new parts alongside them to link old and new knowledge.
Copy Weights with Re-initialization: Isolate and freeze specific internal parts of the model for each individual task.
Hybrid Methods: Combine structural changes with training rules to get the best of both worlds.
The tradeoff here is scale. Scalability remains an issue with architectural approaches because the network parameters grow as the number of tasks increases. This becomes a significant constraint in production deployments where dozens or hundreds of tasks may accumulate over time. Hybrid methods have shown more balanced results in recent benchmarks.
What Are the Three Learning Scenarios in Continual Learning?
Researchers also categorize continual learning by the type of task shift the model encounters. There are three standard scenarios.
In task-incremental learning, the model knows which task it is performing at test time. Task identity is available as context.
In domain-incremental learning, the task category remains the same but the input distribution shifts. For example, a sentiment classifier trained on product reviews that then encounters social media text faces a domain shift without a task shift.
In class-incremental learning, the model must classify an expanding set of classes with no task identity provided at inference time. Class-incremental learning is recognized as one of the most challenging scenarios in the field and has been the subject of dedicated survey work in the IEEE Transactions on Pattern Analysis and Machine Intelligence. This is the scenario closest to real-world deployment conditions.
How is Continual Learning Being Applied to Large Language Models (LLMs)?
Traditional AI models are trained once on a fixed dataset, which means their knowledge quickly becomes outdated. For modern LLMs to stay useful, they must constantly learn new information without forgetting the information that they already know.
Because LLMs are massive and generate text in a step-by-step manner, older AI learning methods do not work well. Instead, engineers apply continual learning across three distinct stages of an LLM's life cycle:
Continual Pre-training: This involves injecting fresh, real-world data and new domain knowledge into the base model.
Continual Fine-tuning: Here, the model is taught how to perform new specific tasks or follow new instructions.
Continual Alignment: This involves correcting the model's behavior to keep it safe, helpful, and accurate over time.
To update these massive models efficiently without breaking their existing knowledge, researchers depend on parameter-efficient tools like LoRA (Low-Rank Adaptation), specialized scaling laws, and Mixture-of-Experts systems.
Where is Continual Learning Being Used in the Real World?
Continual learning is actively used in real-world engineering and production systems. Tech companies, automotive manufacturers, and medical researchers have deployed specific frameworks to handle streaming data without deleting past knowledge.
Deployment examples of Continual Learning from real world implementations across multiple industries:
1. Large Language Models (LLMs) & Finance: BloombergGPT
Implementation: Financial firms cannot depend only on static LLMs because market terms, stock tickers, and economic contexts change daily. In developing BloombergGPT, researchers utilized Domain-Adaptive Continual Pre-training (DAPT).
How it works: Instead of retraining a massive model from scratch when new data arrives, they continually feed a streaming, unlabeled financial corpus into an existing general language model. This infuses new domain terminology into the model's parameters while maintaining its base reasoning capabilities.
2. Autonomous Driving: Tesla’s Occupancy Network
Implementation: In autonomous systems, a self-driving vehicle cannot completely reset its artificial intelligence every time it encounters a new city, unique weather, or rare construction zones.
How it works: Tesla transitioned its Full Self-Driving (FSD) stack toward an end-to-end world model network. The vision system processes vast streams of video data collected across millions of vehicles. It uses data-driven joint loss functions to compress new driving scenarios directly into the network parameters. This is done without erasing fundamental navigation rules like lane-keeping and braking.
3. Recommendation Systems: Pinterest (PinSage) & Alibaba (AliGraph)
Implementation: E-commerce and social media platforms experience massive "data drift" as user trends change hourly. Therefore, reconstructing a global recommendation matrix every day is computationally impossible.
How it works: According to production research compiled by Emerald Insight and the ACM Digital Library, systems like Pinterest's PinSage and Alibaba's AliGraph operate on massive graph structures containing billions of edges. They use streaming dataset distillation and incremental graph updates. When a user interacts with a new product, the system performs a localized gradient update to capture the immediate change in taste without forgetting the user's historical core preferences.
4. Healthcare AI: Multi-Hospital EHR & Imaging Deployments
The Implementation: If a diagnostic model trained at Hospital A is deployed at Hospital B, it faces new patient demographics and different imaging equipment. Simply fine-tuning the model on Hospital B's data causes "catastrophic forgetting.” This makes it less accurate when analyzing data from Hospital A.
How it works: Real-world clinical research documented in Nature and The Lancet Digital Health shows the use of experience replay-based clinical agents. As the AI adapts to new patient cohorts sequentially (Hospital A → Hospital B → Hospital C), it retains a tiny, securely anonymized memory buffer of historical patient cases. The model replays past data alongside new data to balance "rigidity" (saving old knowledge) and "plasticity" (learning new hospitals).
What are the Challenges of Continual Learning?
The field has made real progress. However, several hard problems persist.
First, there is no universal benchmark. Comparing different AI systems remains highly difficult because researchers use entirely different datasets, test orders, and scoring metrics to evaluate their models.
Second is strategy conflicts. Using a combination of three core strategy families (regularization, replay, and changing model architecture) into a single, cohesive system is incredibly complex; often, one method accidentally cancels out the benefits of another.
Third, fairness and bias amplification remain underexplored. As an AI continuously updates on streaming data from the real-world, it risks absorbing and compounding societal biases, stereotypes, or errors present in newer datasets over time.
Fourth is recency and task bias. Models naturally develop a heavy blind spot called recency bias. It causes them to over-favor newly introduced data profiles while discarding historical context
Open research directions include memory-efficient learning, adaptive self-supervised techniques, and fairness-aware continual learning, all of which are needed before continual learning systems can be deployed responsibly at scale.
What Does the Future of Continual Learning Look Like?
For continual learning, the trajectory is clear. As AI systems are expected to operate for years in our changing world, the ability to learn without forgetting has become non-negotiable.
One of the most urgent tasks in AI at present is to keep giant language models up to date with fresh facts and dynamic user preferences. In fact, a dedicated tutorial at the 2025 EMNLP conference highlighted the importance of this issue in modern AI engineering.
The next exciting frontiers include:
Brain-Inspired Memory: Developing AI systems that mimic the human brain by separating quick, everyday experiences (episodic memory) from long-term factual knowledge (semantic memory).
Multimodal Learning: Teaching AI to continuously learn from text, images, video, and audio all at the same time without breaking.
Expanding Across AI Types: Moving beyond text to apply continual learning to vision-language models, robotics, and image-generating diffusion models.
Continual learning is essentially trying to build a fundamental biological capability into software. The challenge is incredibly hard, the stakes are high, and the field is moving so fast that cutting-edge methods implemented today might be outdated by the time a company finishes deploying it.
Latest Blogs
8- PhD in Business Careers: Academic and Industry Paths After Graduation (2026 Guide)
- Is an Online DBA Worth It? Salary, ROI, and Career Benefits (2026 Guide)
- PhD vs DBA: Which Doctorate Is Right for You? (2026 Complete Guide)
- How to Compare Online DBA Programs: A Step-by-Step Guide Before You Apply
- Doctor of Business Administration Careers: Jobs, Salary & Growth in 2026
- Why Does a DBA Make More Sense Than a PhD?
- DBA vs PhD: Which Doctoral Degree Holds Higher Academic Value?
- Online DBA Degree Explained: Curriculum, Admission, and Career Opportunities (2026 Guide)
Priyank Jha
Priyank is a Senior Content Developer and Strategist at SNVA Veranda. Earlier, he worked as a data scientist, where he gained extensive experience in developing data-driven solutions, advanced analytics, and strategic decision-making processes. His expertise includes data analysis, business intelligence, and implementing data-centric strategies that drive organizational growth and innovation. In addition to his data science experience, Priyank has over 10 years of experience in the banking and financial services sector. He has worked across various roles and operational levels, gaining in-depth knowledge of financial operations, customer service management, and business processes.
Learn how we research, review, and update our content. Editorial Standards & Review Process.